

पायथन में BeautifulSoup के साथ वेब स्क्रैपिंग
वेब स्क्रैपिंग क्या है?
वेब स्क्रैपिंग को "वेबसाइटों या इंटरनेट से डेटा निकालने" के रूप में परिभाषित किया जाता है और यह वही है — वेबसाइटों को स्वचालित रूप से पढ़ने, कुछ खोजने, या उनसे किसी प्रकार की जानकारी को सहेजने के लिए पेज स्रोतों को देखने के लिए कोड का उपयोग करना।
इसका उपयोग हर जगह किया जाता है, गूगल बॉट्स द्वारा वेबसाइटों को इंडेक्स करने से लेकर, खेल आंकड़ों पर डेटा एकत्र करने तक, स्टॉक मूल्यों को एक्सेल स्प्रेडशीट में सहेजने तक — विकल्प वास्तव में असीमित हैं। यदि आप किसी साइट, पेज या खोज शब्द में रुचि रखते हैं और उसके बारे में अपडेट चाहते हैं, तो यह लेख आपके लिए है — हम Python के साथ वेबसाइटों से डेटा एकत्र करने के लिए requests और BeautifulSoup लाइब्रेरीज का उपयोग कैसे करें, इस पर एक नज़र डालेंगे, और आप आसानी से अपने सीखे हुए कौशल को किसी भी वेबसाइट को स्क्रैप करने में आसानी से स्थानांतरित कर सकते हैं जो आपको रुचिकर लगती है।
हम किन टूल्स का उपयोग करेंगे?
Python इंटरनेट से डेटा स्क्रैप करने के लिए पसंदीदा भाषा है, और requests और BeautifulSoup लाइब्रेरीज़ इस काम के लिए सबसे उपयुक्त पायथन पैकेज हैं। इनके साथ requests, आप आसानी से किसी भी वेबसाइट को स्क्रैप कर सकते हैं, और इसके डेटा को कई तरीकों से पढ़ सकते हैं, HTML से लेकर JSON तक। चूंकि अधिकांश वेबसाइट्स HTML से बनी होती हैं और हम पेज से सभी HTML निकालेंगे, इसलिए हम फिर BeautifulSoup पैकेज का उपयोग करेंगे bs4 से उस HTML को पार्स करने और उसमें हमें जो डेटा चाहिए उसे खोजने के लिए।
आवश्यकताएँ
इसका अनुसरण करने में सक्षम होने के लिए, आपको Python, requests, और BeautifulSoup इंस्टॉल करने की आवश्यकता होगी।
-
Python: आप Python का नवीनतम संस्करण आधिकारिक वेबसाइटसे डाउनलोड कर सकते हैं, हालांकि बहुत संभव है कि आपने इसे पहले से ही इंस्टॉल कर रखा है।
-
requests: यदि आपके पास Python संस्करण >= 3.4 है, तो आपके पासpipइंस्टॉल है। आप फिरpipका उपयोग कमांड लाइन में किसी भी डायरेक्टरी मेंpython3 -m pip install requestsटाइप करके कर सकते हैं। -
BeautifulSoup: यहbs4के तहत पैकेज किया गया है, लेकिन आप इसे आसानी सेpython3 -m pip install beautifulsoup4.
प्रोग्रामिंग
के साथ इंस्टॉल कर सकते हैं मेरा मानना है कि प्रोग्रामिंग सीखने का सबसे अच्छा तरीका करके और एक प्रोजेक्ट बनाकर है, इसलिए मैं आपको दृढ़ता से प्रोत्साहित करता हूं कि आप अपने पसंदीदा टेक्स्ट एडिटर (मैं Visual Studio Code की सिफारिश करता हूं) में मेरे साथ फॉलो करें जैसे-जैसे हम इन दो लाइब्रेरीज़ का उपयोग उदाहरण के माध्यम से सीखते हैं।
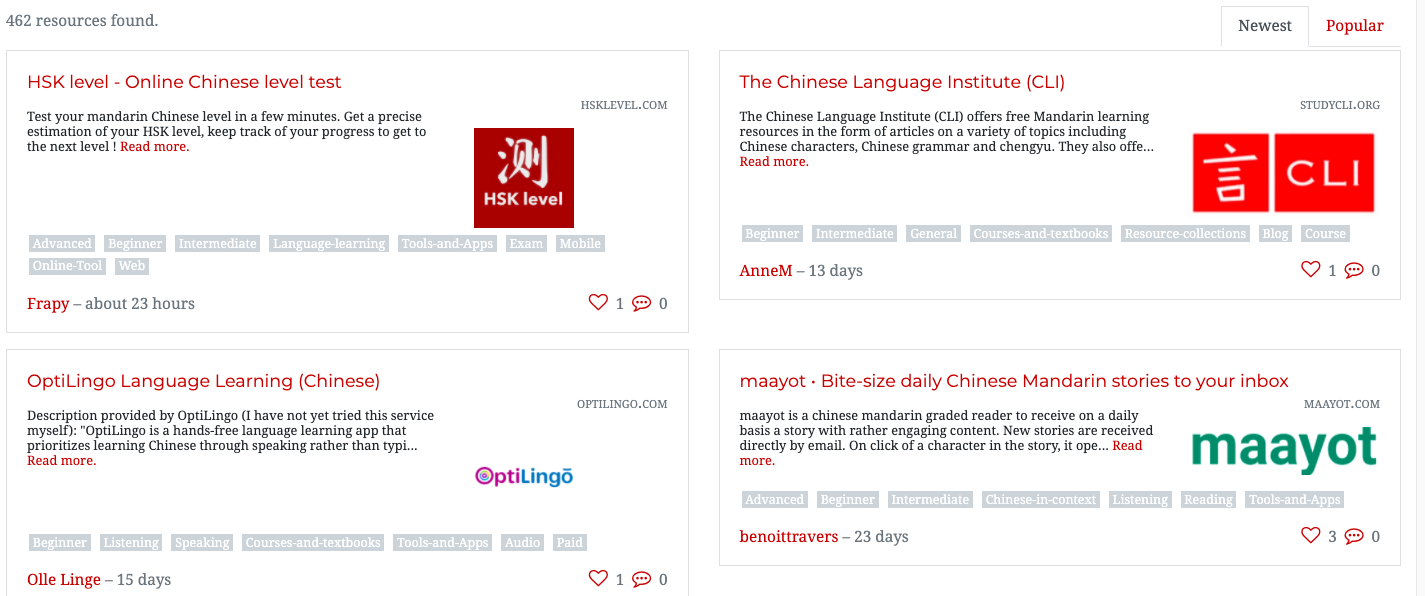
चूंकि मैं मंदारिन सीख रहा हूं, मुझे लगा कि मंदारिन संसाधनों के लिंक की एक सूची बनाने के लिए एक स्क्रैपर बनाना उचित होगा। सौभाग्य से, मैंने पहले से कुछ शोध किया और पता चला कि वहां है एक ऑनलाइन वेबसाइट है जो मंदारिन संसाधनों की कार्ड जैसी सूचियों को संग्रहित करती है। हालांकि, ये लगभग एक दर्जन पृष्ठों में फैले हुए हैं, कार्ड रूप में, और कई लिंक टूटे हुए हैं। वह वेबसाइट जिससे हम इन लिंक्स को स्क्रैप करेंगे एक प्रसिद्ध मंदारिन सीखने की वेबसाइट है, और आप संसाधन सूची यहां देख सकते हैं: https://challenges.hackingchinese.com/resources.
तो, इस प्रोजेक्ट में, हम उस सूची से काम करने वाले लिंक स्क्रैप करेंगे और उन्हें अपने कंप्यूटर पर एक फ़ाइल में सहेजेंगे, ताकि हम बाद में अपने आराम से उनके माध्यम से जा सकें बिना साइट पर हर कार्ड पर क्लिक करने की आवश्यकता के। पूरा प्रोग्राम केवल ~40 लाइन कोड का होगा, और हम प्रोजेक्ट पर तीन अलग-अलग चरणों में काम करेंगे।
साइट का विश्लेषण
वास्तविक प्रोग्रामिंग शुरू करने से पहले, हमें देखना होगा कहाँ डेटा वेबसाइट पर संग्रहीत किया जा रहा है। यह पृष्ठ का "निरीक्षण" करके किया जा सकता है। आप पृष्ठ के किसी भी स्थान पर राइट-क्लिक करके और फिर "निरीक्षण" का चयन करके पृष्ठ का निरीक्षण कर सकते हैं। यदि आप उसका चयन करते हैं, तो यह आपकी स्क्रीन के नीचे पृष्ठ का स्रोत कोड लाएगा, एक बहुत सारा डराने वाला दिखने वाला HTML। चिंता न करें — BeautifulSoup लाइब्रेरी इसे हमारे लिए आसान बना देगी।
हम वेबसाइट पर पहले परिणाम का "निरीक्षण" करने जा रहे हैं https://challenges.hackingchinese.com/resources, नामतः HSK level — Online Chinese level test। ऐसा करने के लिए, हमें अपना माउस ठीक उसके ऊपर रखना होगा जिसे हम स्क्रैप करना चाहते हैं — जो कि शीर्षक है, क्योंकि यह एक लिंक भी है — और फिर "निरीक्षण" पर क्लिक करें, जो स्रोत कोड खोलेगा और हमें ठीक वहीं ले जाएगा जहां हम होना चाहते हैं — लिंक पर।
यदि आप ऐसा करते हैं, तो आपको नीचे दिए गए जैसा कुछ दिखाई देना चाहिए:
class="card-title" style="font-size: 1.1rem">
href="http://www.hsklevel.com">HSK level — Online Chinese level test
बहुत अच्छी खबर! ऐसा लगता है कि प्रत्येक लिंक एक h4 हेडर के अंदर है। जब भी हम डेटा के लिए किसी वेबसाइट को स्क्रैप करते हैं, तो हमें उस डेटा के लिए अद्वितीय "पहचानकर्ता" को देखना होता है। इस मामले में, यह h4 हेडर है, क्योंकि साइट पर कोई अन्य नहीं है जो लिंक से संबंधित न हो। एक अन्य विकल्प font-size या class के card-titleके आधार पर खोज करना हो सकता है, लेकिन हम h4 हेडर के लिए जाएंगे क्योंकि यह सबसे सरल है।
संसाधन लिंक्स की स्क्रैपिंग
अब जब हमने वेबसाइट स्रोत कैसा दिखता है यह समझ लिया है, तो हमें वास्तव में सामग्री स्क्रैप करने की ओर बढ़ना चाहिए। हम प्रत्येक लिंक को अपने डिवाइस पर एक फ़ाइल में सहेजेंगे जिसका नाम है links.txt, और काम पूरा करने के लिए हमें बस कुछ दर्जन पंक्तियों की आवश्यकता है।
चलिए शुरू करते हैं।
- लाइब्रेरी आयात करना
प्रोग्राम चलाने के लिए हमें पूर्वोक्त लाइब्रेरी की आवश्यकता है। नाम की एक नई फ़ाइल बनाएंscrape_links.pyऔर निम्नलिखित लिखें:
import requests, time bs4 import BeautifulSoup - साइट स्क्रैप करना
चूंकि वेबसाइट के संसाधन कई पृष्ठों में विभाजित हैं, इसलिए इसे एक फ़ंक्शन के भीतर स्क्रैप करना समझदारी है ताकि हम इसे दोहरा सकें। आइए इस फ़ंक्शन का नाम रखेंextract_resources, और इसमें एक पैरामीटर होगा जो इसके पृष्ठ संख्या को परिभाषित करेगा।
def extract_resources(page: int -> None): # use an f-string to access the correct page page = requests.get(f'https://challenges.hackingchinese.com/resources/stories?page={page}) soup = BeautifulSoup(page.content, 'html.parser')हम वेबसाइट के
soupऑब्जेक्ट को रखने के लिएBeautifulSoupवेरिएबल का उपयोग कर रहे हैं। हम इसेhtml.parserके साथ HTML में परिवर्तित कर रहे हैं और जिस डेटा को हम परिवर्तित कर रहे हैं वहpageवेरिएबल की सामग्री है।links = soup.find_all('h4')हम उस सभी HTML को खोजने के लिए
BeautifulSoupका उपयोग करेंगे जो हेडर हैं, और उन्हें उनके बच्चे html (इस मामले में, लिंक) के साथlinksनाम की एक सूची में सहेजेंगे। - हमारा डेटा एकत्र करना
for i में range(len(links)): try: if links[i]['class'] == ['card-title']: true_links.append(links[i]) except: passपहली पंक्ति में, हम
linksमें प्रत्येक h4 हेडर के माध्यम से पुनरावृत्ति कर रहे हैं। हम यह जांचते हैं कि क्या इसकी क्लास हैcard-title, जैसा कि हमने देखा था साइट का विश्लेषण, ताकि यह सुनिश्चित किया जा सके कि हम किसी भी ऐसे h4 हेडर से बचें जो कार्ड नहीं हैं — सिर्फ सावधानी के लिए। यदि यह एक लिंक वाला कार्ड-संबंधित h4 है, तो हम इसे पहले से खाली सूची में जोड़ देंगेtrue_linksसभी के साथ सही h4s.
अंत में, हम इसे एकtry: except:लूप में लपेटेंगे यदि h4 का कोई केस नहीं है, ताकि प्रोग्राम को क्रैश होने से रोका जा सके क्योंकिBeautifulSoupअनुरोध को संभाल नहीं सकता। - लिंक्स को सहेजना
# open file with w+ (generate it if it does not exist) file = open("links.txt", "w+") for i में range(len(true_links)): file.write(str(list(true_links[i].children)[0]['href']) + '\n') file.close()सूची को प्रिंट करने के बजाय, आइए इसे सहेज लें ताकि हमें Python फ़ाइल को कई बार चलाने की आवश्यकता न हो और इसे एक आसान-से-देखने वाले प्रारूप में रखा जा सके।
सबसे पहले, हम फ़ाइल खोलते हैं, और हम इसे खोल रहे हैंw+ताकि अगर यह मौजूद नहीं है, तो हम इसके नाम से एक खाली फ़ाइल बना सकें।
दूसरा, हमtrue_linksकी सूची के माध्यम से पुनरावृत्ति करते हैं। प्रत्येक तत्व के लिए, हम फ़ाइल में इसके लिंक का उपयोग करके लिखते हैंfile.write()। जब हम पहली बार साइट का विश्लेषण कर रहे थे, तो हमने देखा कि लिंक h4 HTML हेडर का एक चाइल्ड एलिमेंट है। इसलिए, हमBeautifulSoupका उपयोग करते हैंtrue_links[i]के पहले चाइल्ड तक पहुंचने के लिए, जिसे हमें एक सूची में लपेटना होगा क्योंकि यह अन्यथा एक Python ऑब्जेक्ट है।
इस बिंदु पर, हमारे पास हैlist(true_links[i].children)[0]। हालाँकि, हम जो खोज रहे हैं वह चाइल्ड का वास्तविक लिंक है। के बजायTextहम केवल लिंक चाहते हैं, जिसे हम इसके साथ एक्सेस कर सकते हैं['href']. एक बार जब हमारे पास यह हो जाए, तो हमें पूरी चीज को एक स्ट्रिंग में लपेटना होगा ताकि यह एक स्ट्रिंग के रूप में आउटपुट हो और फिर '\n' जोड़ना होगा ताकि यह सुनिश्चित हो सके कि प्रत्येक लिंक नई पंक्ति पर है जब हमfile.write()इसे।
अंत में, हम करते हैंfile.close()हमारे द्वारा खोली गई फ़ाइल को बंद करने के लिए।
यदि आप प्रोग्राम चलाते हैं और इसे कुछ मिनट देते हैं, तो आपको पता चलेगा कि अब आपके पास एक फ़ाइल है जिसका नाम हैlinks.txtके साथ सैकड़ों लिंक्स का जो हमने पायथन से स्क्रैप किया था! बधाई हो! पायथन के बिना, प्रत्येक URL को मैन्युअल रूप से पकड़ने में बहुत अधिक समय लगता।
इसे समाप्त करने से पहले, हम एक और तरीका देखने जा रहे हैं जिसमें हम उपयोग कर सकते हैंrequestsप्रत्येक लिंक की स्थिति की जांच करके लाइब्रेरी।
बोनस: मृत लिंक्स को हटाना
जिस वेबसाइट को हम स्क्रैप कर रहे हैं उसे अच्छी स्थिति में नहीं रखा गया है, और कुछ लिंक पुराने या पूरी तरह से मृत हैं। तो, इस वैकल्पिक चरण में, हम स्क्रैपिंग का एक और पहलू देखेंगे जो प्रत्येक वेबसाइट की स्थिति कोड लौटाता है, और उन्हें खारिज कर देता है यदि यह 404 है — जिसका अर्थ है नहीं मिला।
हमें ऊपर दिए गए चरण 4 में उपयोग किए गए कोड को थोड़ा संशोधित करने की आवश्यकता होगी। लिंक के माध्यम से केवल पुनरावृत्ति करने और उन्हें फ़ाइल में लिखने के बजाय, हम पहले यह सुनिश्चित करने जा रहे हैं कि वे टूटे हुए नहीं हैं।
file = open("links.txt", "w+")
for i में range(len(true_links)):
try:
# ensure it is a working link
response = requests.get(str(list(true_links[i].children)[0]['href']), timeout = 5, allow_redirects = True, stream = True)
if response != 404:
file.write(str(list(true_links[i].children)[0]['href']) + '\n')
except: # Connection Refused
pass
file.close()
हमने कुछ परिवर्तन किए हैं — आइए उन पर एक नज़र डालें।
- हमने बनाया एक
responseवेरिएबल जो लिंक के स्टेटस कोड की जांच करता है - मूल रूप से यह देखता है कि वह अभी भी मौजूद है या नहीं। यह उपयोगीrequests.get()विधि से किया जा सकता है। हम वही लिंक प्राप्त कर रहे हैं जिसे हम जोड़ने की कोशिश कर रहे हैं, यानी वेबसाइट URL, और इसे प्रतिक्रिया देने के लिए 5 सेकंड दे रहे हैं, रीडायरेक्ट करने का मौका दे रहे हैं, और हमें फाइलें भेजने की अनुमति दे रहे हैं (जिन्हें हम डाउनलोड नहीं करेंगे), इसके साथstream = True. - हमने यह जांचा कि प्रतिक्रिया क्या थी, यह देखकर कि यह 404 था या नहीं। अगर यह नहीं था, तो हमने लिंक लिखा, लेकिन अगर यह था, तो हमने कुछ नहीं किया और फाइल में लिंक नहीं लिखा। यह सशर्त के माध्यम से किया गया था
if response != 404. - अंत में, हमने पूरी चीज को एक try - except लूप में लपेट दिया। ऐसा इसलिए है क्योंकि अगर पेज लोड होने में धीमा था, उस तक पहुंचा नहीं जा सकता था, या कनेक्शन अस्वीकार कर दिया गया था, तो सामान्य तौर पर प्रोग्राम एक अपवाद में क्रैश हो जाएगा। हालांकि, चूंकि हमने इसे इस लूप में लपेट दिया है, इसलिए अपवाद के मामले में कुछ नहीं होगा और इसे केवल पास कर दिया जाएगा।
और बस इतना ही! यदि आप कोड चलाते हैं (और इसे चलता भी रहने देते हैं, क्योंकि requests सैकड़ों लिंक की जांच करने के लिए इसे एक अच्छा आधा घंटा लग सकता है) जब यह समाप्त होता है तो आपके पास कुछ सौ कार्यशील संसाधन लिंक का एक सुंदर सेट होगा!
पूरा कोड
# grab the list of all the resources at https://challenges.hackingchinese.com/resources
import requests, time
bs4 import BeautifulSoup
# links that hold the correct content, not headers and other HTML
true_links = []
def extract_resources(page: int) -> None:
page = requests.get(f'https://challenges.hackingchinese.com/resources/stories?page={page}')
soup = BeautifulSoup(page.सामग्री, 'html.parser')
# links are stored within a unique header on each card
links = soup.find_all('h4')
for i में range(len(links)):
try:
if links[i]['class'] == ['card-title']:
true_links.append(links[i])
except:
pass
for i में range(1, 10):
extract_resources(i) # 9 different pages with info
file = open("links.txt", "w+")
for i में range(len(true_links)):
try:
# ensure it is a working link
response = requests.get(str(list(true_links[i].children)[0]['href']), timeout = 5, allow_redirects = True, stream = True)
if response != 404:
file.write(str(list(true_links[i].children)[0]['href']) + '\n')
except: # Connection Refused
pass
file.close()
निष्कर्ष
इस पोस्ट में, हमने सीखा है कि कैसे:
- पेज स्रोत देखें
- किसी वेबसाइट से विशिष्ट डेटा स्क्रैप करें
- Python के साथ फ़ाइलों में लिखें
- मृत लिंक के लिए जाँच करें
यद्यपि हमने केवल उचित लाइब्रेरीज़ के साथ Python में किए जा सकने वाले वेब स्क्रैपिंग के प्रकार की सतह को ही छुआ है, मुझे आशा है कि यह त्वरित परिचय भी आपको वेबसाइटों को स्वचालित रूप से स्क्रैप करने के लिए प्रोग्रामिंग की शक्ति का लाभ उठाने का तरीका सिखा दिया होगा। मैं आपको दोनों के आधिकारिक दस्तावेज़ीकरण को देखने के लिए दृढ़ता से प्रोत्साहित करता हूं requests और BeautifulSoup यदि आप डेटा स्क्रैपिंग की दुनिया में गहरी डुबकी लगाना चाहते हैं, और देखना चाहते हैं कि क्या कोई डेटा है जो आप वेब से एकत्र कर सकते हैं और अपने स्वयं के प्रोजेक्ट्स में उपयोग कर सकते हैं।
टिप्पणियों में मुझे बताएं कि आप क्या स्क्रैप कर रहे हैं या यदि आपको किसी और मदद की आवश्यकता है!
हैप्पी कोडिंग!
टिप्पणी करें